[프로그래머스] 위클리 챌린지 6주차 : 복서 정렬하기(python)
[문제 설명]
코딩테스트 연습 - 6주차_복서 정렬하기
복서 선수들의 몸무게 weights와, 복서 선수들의 전적을 나타내는 head2head가 매개변수로 주어집니다. 복서 선수들의 번호를 다음과 같은 순서로 정렬한 후 return 하도록 solution 함수를 완성해주세요
programmers.co.kr
[나의 답안]
def solution(weights, head2head):
WEIGHT = 0
WIN_COUNT = 1
WIN_COUNT_OW = 2
boxer_info_dict = {num: [weight] for num, weight in enumerate(weights)}
for i, record in enumerate(head2head):
record = list(record)
win_count = record.count('W')
lose_count = record.count('L')
if win_count + lose_count != 0:
boxer_info_dict[i].append(win_count/(win_count + lose_count))
else:
boxer_info_dict[i].append(0)
search_idx = 0
win_count_overweight = 0
for _ in range(win_count):
opponent_idx = search_idx + record[search_idx:].index('W')
my_weight = boxer_info_dict[i][WEIGHT]
your_weight = boxer_info_dict[opponent_idx][WEIGHT]
if my_weight < your_weight:
win_count_overweight += 1
search_idx = opponent_idx + 1
boxer_info_dict[i].append(win_count_overweight)
answer = [num[0]+1 for num in sorted(boxer_info_dict.items(), key=lambda x:(x[1][WIN_COUNT], x[1][WIN_COUNT_OW], x[1][WEIGHT], -x[0]), reverse=True)]
return answer어쩌다 보니, 2시간 넘게 풀어버렸다.
승률로 비교를 해야되는데 승수만 비교하려고 꼼수를 쓰려다가, 왜 자꾸 틀리는 지 생각하기보다 짜증만 내다가 문제점을 찾았다.
WWNNL 과, WWNNN 인 사람의 승률을 비교해보면, 66%, 100% 이기 때문에 win_count로 비교하면 안된다는 것을 거의 2시간만에 깨우쳤다. 되게 한심하게 시간을 썼다..
2중 for loop이 너무 심플하고 쉬운 방법 같아서, 먼저 win_count를 구한 후 count 횟수 만큼 비교를 하려고 코드를 이렇게 짰는데,
생각해보니 win_count를 구하는 과정에서 for문이 돌아가기 때문에, 더 비효율 적인 것 같다.
아래 접은 글( 더보기 )에서, 다른 사람의 코드와 실행속도를 비교해 봤다.
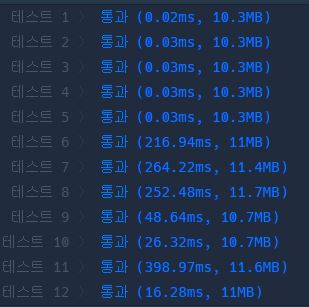
2중 for loop 돌린 사람과 테스트를 해봤더니, 평균적으로 내 코드 수행시간이 훨씬 느리게 나왔다.
근데 메모리는 내가 조금 적게 썼다. 개선해봐야지!
그래도 뿌듯한 건, sorted 안에 lambda 식을 직접 처음 써본 점이다.
- 내림차순 : 승률(1순위), 초과무게 승리 수(2순위), 무게(3순위)
- 오름차순 : 선수 번호(4순위) 를 위해
key=lambda x:(x[1][WIN_COUNT], x[1][WIN_COUNT_OW], x[1][WEIGHT], -x[0]), reverse=True 와 같이 코드를 구성했다.
※회고
1. 변수명 바꾸기 : 오랜 시간 동안 오류를 찾으려고 끙끙대다가, 승률을 WIN_COUNT라고 적어두었다 → 수정
다른 몇몇 변수들도 바꿨다.
2. 2중 for loop로 변경
def solution(weights, head2head):
WEIGHT = 0
WIN_RATE = 1
WIN_OVERWEIGHT_COUNT = 2
boxer_info_dict = {num: [weight] for num, weight in enumerate(weights)}
for i in range(len(head2head)):
record = list(head2head[i])
win_count = 0
lose_count = 0
win_overweight_count = 0
for j in range(len(head2head)):
if head2head[i][j] == 'W':
win_count += 1
my_weight = boxer_info_dict[i][WEIGHT]
your_weight = boxer_info_dict[j][WEIGHT]
if my_weight < your_weight:
win_overweight_count += 1
elif head2head[i][j] == 'L':
lose_count += 1
try:
boxer_info_dict[i].append((win_count / (win_count + lose_count)))
except:
boxer_info_dict[i].append(0)
boxer_info_dict[i].append(win_overweight_count)
answer = [num[0]+1 for num in sorted(boxer_info_dict.items(), key=lambda x:(x[1][WIN_RATE], x[1][WIN_OVERWEIGHT_COUNT], x[1][WEIGHT], -x[0]), reverse=True)]
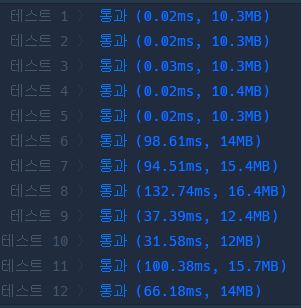
return answer수정 하고 나서, 이전 코드와 수행시간 및 메모리를 비교해보니 아래와 같다.
평균 메모리 사용량도 조금 줄고, 수행속도가 많이 개선되었다.

