[공모주 알리미 개발] 2-2. ipostock 크롤링 : 주주구성, 공모정보, 수요예측 정보 가져오기
공모주 알리미 만들기[2-1. ipostock 크롤링 : 종목별 url 추출하기]
공모주 관련 정보를 크롤링할 사이트로 38 커뮤니케이션, ipostock 두 가지를 알아봐 두었다. 그중, 먼저 아래 ipostock 사이트에서 공모주 관련 정보를 크롤링하려고 한다. 아이피오스탁(IPOSTOCK)-IPO공
hzoo.tistory.com
앞 글에서 추출한 url을 통하여, 해당 url 안의 주주구성, 공모정보, 수요예측 정보를 가져오려고 한다.
주주구성, 공모정보, 수요예측 정보를 눌러보면 url이 변경되는 것을 볼 수 있다.
현대중공업을 예로 들면 아래와 같다.
- 주주구성 탭 : http://www.ipostock.co.kr/view_pg/view_02.asp?code=B202105072
- 공모정보 탭 : http://www.ipostock.co.kr/view_pg/view_04.asp?code=B202105072
- 수요예측 탭 : http://www.ipostock.co.kr/view_pg/view_05.asp?code=B202105072
따라서, 아래 코드와 같이 각 탭의 index를 직관적으로 보기 위해 IntEnum으로 선언하였고, 크롤링 할 url들을 url_list에 넣어주었다. (앞 글에서 url을 추출했을 때, 공모정보 탭을 href 값으로 가지고 있었다)
import requests
from bs4 import BeautifulSoup
from enum import IntEnum
import pandas as pd
class UrlTypeIndex(IntEnum):
PUBLIC_OFFERING = 0 #공모정보
SHARE_HOLDER = 1 #주주구성
DEMAND_FORECAST = 2 #수요예측
def crawl_ipo_info(url):
url_list = []
url_list.append(url) # 공모정보 탭
for page_num in [2, 5]: # 주주구성, 수요예측 탭
search_required_url = url.replace('_04', f'_0{page_num}')
url_list.append(search_required_url)
bidding_info_df = get_bidding_info_df(url_list[UrlTypeIndex.PUBLIC_OFFERING])
company_name = bidding_info_df['종목명']
underwriter_df = get_underwriter_df(url_list[UrlTypeIndex.PUBLIC_OFFERING], company_name)
shares_info_df = get_shareholder_info_df(url_list[UrlTypeIndex.SHARE_HOLDER], company_name)
ipo_info_df = pd.merge(bidding_info_df, shares_info_df)
try:
demand_forecast_result_df = get_demand_forecast_result_df(url_list[UrlTypeIndex.DEMAND_FORECAST], company_name)
demand_forecast_band_info_df = get_demand_forecast_band_info_df(url_list[UrlTypeIndex.DEMAND_FORECAST], company_name)
ipo_info_df = pd.merge(ipo_info_df, demand_forecast_result_df)
except IndexError:
#청약 전날에 수요예측 결과가 늦게 표기되는 경우가 종종 있음
print("수요예측 결과 미표기")
return ipo_info_df그리고 각 탭에 맞춰 크롤링 하는 코드를 작성하였다.
나중에 DB에 넣기 용이하도록 pandas의 데이터프레임 형태로 데이터를 받아왔고, 종목명을 기준으로 데이터 프레임을 merge 해줘서 하나로 합쳤다.
- 수요예측 밴드정보(demand_forcast_band_info_df), 주간사 정보(underwriter_df) 같은 경우 DB에 저장할 때 다른 table에 저장하기 위해서, 일단 ipo_info_df에 merge하지 않았다.
- try-except 문 같은 경우, 주석에도 적어놨듯이 청약 전날에 수요예측 결과가 늦게 표기되는 경우가 종종 있으므로 수요예측 결과가 표기되었을 때만 ipo_info_df에 merge해주도록 코드를 작성하였다.
아래에서 공모정보, 주주구성, 수요예측 탭 순서대로 크롤링 하는 코드들을 설명하려고 하며,
전체 코드는 맨 마지막에 펼처서 첨부하려고 한다.
<1. 공모정보 탭 크롤링하기 : UrlTypeIndex.PUBLIC_OFFERING>
아래 더보기 : 사진 및 코드 - 사진에 코드 이해를 위한 필기 기입(아이패드 요놈 좋네..)
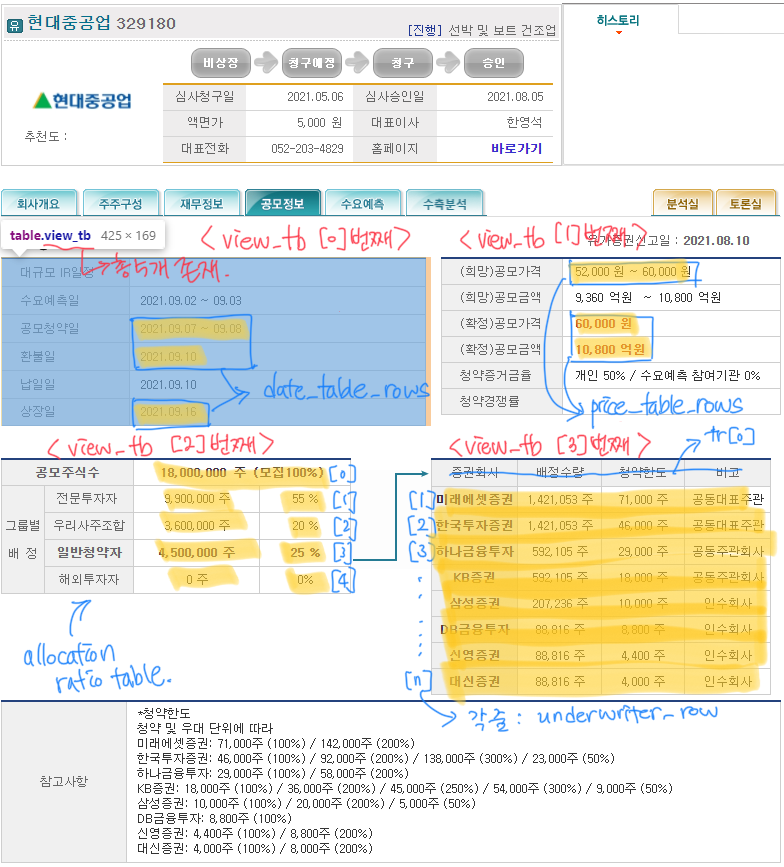
def get_bidding_info_df(url):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
tables = soup.select('table[class="view_tb"]')[0:3]
company_name = soup.find('strong', {'class': 'view_tit'}).text.strip()
date_table = tables[0]
price_table = tables[1]
allocation_ratio_table = tables[2]
date_df = get_date_info_df(date_table, company_name)
offering_price_df = get_offering_price_info_df(price_table, company_name)
allocation_ratio_df = get_allocation_ratio_df(allocation_ratio_table, company_name)
bidding_info_df = pd.merge(date_df, offering_price_df)
bidding_info_df = pd.merge(bidding_info_df, allocation_ratio_df)
return bidding_info_df
def get_date_info_df(date_table, company_name):
date_table_rows = date_table.find_all('tr')[2:]
del date_table_rows[-2]
temp_ipo_date_info = date_table_rows[0].find_all('td')[1].text.strip().replace('\xa0', '').replace(" ", "")
offering_start = temp_ipo_date_info[:10]
offering_finish = temp_ipo_date_info[:5] + temp_ipo_date_info[-5:]
refund_date = date_table_rows[1].find_all('td')[1].text.strip().replace('\xa0', '').replace(" ", "")
ipo_date = date_table_rows[2].find_all('td')[1].text.strip().replace('\xa0', '').replace(" ", "")
date_info_df = pd.DataFrame({'종목명': company_name,
'공모시작' : offering_start,
'공모마감' : offering_finish,
'환불일' : refund_date,
'상장일' : ipo_date}, index=[0])
return date_info_df
def get_offering_price_info_df(price_table, company_name):
price_table_rows = price_table.find_all('tr')[:-2]
del price_table_rows[1]
offering_price_band = price_table_rows[0].find_all('td')[1].text.strip().replace('\xa0', '').replace(' ', '').replace('원', '')
offering_price_band_low, offering_price_band_high = offering_price_band.split('~')
offering_price = price_table_rows[1].find_all('td')[1].text.strip().replace('\xa0', '').replace(' ', '').replace('원', '')
offering_amount = price_table_rows[2].find_all('td')[1].text.strip().replace('\xa0', '').replace(' ', '').replace('원', '')
offering_price_info_df = pd.DataFrame({'종목명': company_name,
'공모가하단' : offering_price_band_low,
'공모가상단': offering_price_band_high,
'공모가격' : offering_price,
'공모규모' : offering_amount}, index=[0])
return offering_price_info_df
def get_allocation_ratio_df(allocation_ratio_table, company_name):
allocation_ratio_table_rows = allocation_ratio_table.find_all('tr')
total_share_num = allocation_ratio_table_rows[0].find_all('td')[1].text.strip().replace('\xa0', '').replace(" ", "") # 0: 공모주식수
investor_num = allocation_ratio_table_rows[1].find_all('td')[2].text.strip().replace(" ", "") #1: 전문투자자
investor_ratio = allocation_ratio_table_rows[1].find_all('td')[3].text.strip().replace(" ", "")
employee_num = allocation_ratio_table_rows[2].find_all('td')[1].text.strip().replace(" ", "") #2: 우리사주조합
employee_ratio = allocation_ratio_table_rows[2].find_all('td')[2].text.strip().replace(" ", "")
public_num = allocation_ratio_table_rows[3].find_all('td')[1].text.strip().replace(" ", "") # 3: 일반청약자
public_ratio = allocation_ratio_table_rows[3].find_all('td')[2].text.strip().replace(" ", "")
foreigner_num = allocation_ratio_table_rows[4].find_all('td')[1].text.strip().replace(" ", "") # 4: 해외투자자
foreigner_ratio = allocation_ratio_table_rows[4].find_all('td')[2].text.strip().replace(" ", "")
allocation_ratio_df = pd.DataFrame({'종목명': company_name,
'공모주식수' : total_share_num,
'전문투자자(주식수)' : investor_num,
'전문투자자(비율)' : investor_ratio,
'우리사주조합(주식수)' : employee_num,
'우리사주조합(비율)' : employee_ratio,
'일반청약자(주식수)' : public_num,
'일반청약자(비율)' : public_ratio,
'해외투자자(주식수)': foreigner_num,
'해외투자자(비율)': foreigner_ratio}, index=[0])
return allocation_ratio_df
def get_underwriter_df(url, company_name):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
underwriter_table = soup.select('table[class="view_tb"]')[3]
underwriter_rows = underwriter_table.find_all('tr')[1:]
underwriter_name_list = []
underwriter_quantity_list = []
for underwriter_row in underwriter_rows:
underwriter_name_list.append(underwriter_row.find_all('td')[0].text.strip().replace(" ", ""))
underwriter_quantity_list.append(underwriter_row.find_all('td')[1].text.strip().replace(" ", ""))
return pd.DataFrame({'종목명': [company_name]*len(underwriter_rows), '주간사' : underwriter_name_list, '배정수량' : underwriter_quantity_list})<2. 주주구성 탭 크롤링하기 : UrlTypeIndex.SHARE_HOLDER>
아래 더보기 : 사진 및 코드 - 사진에 코드 이해를 위한 필기 기입
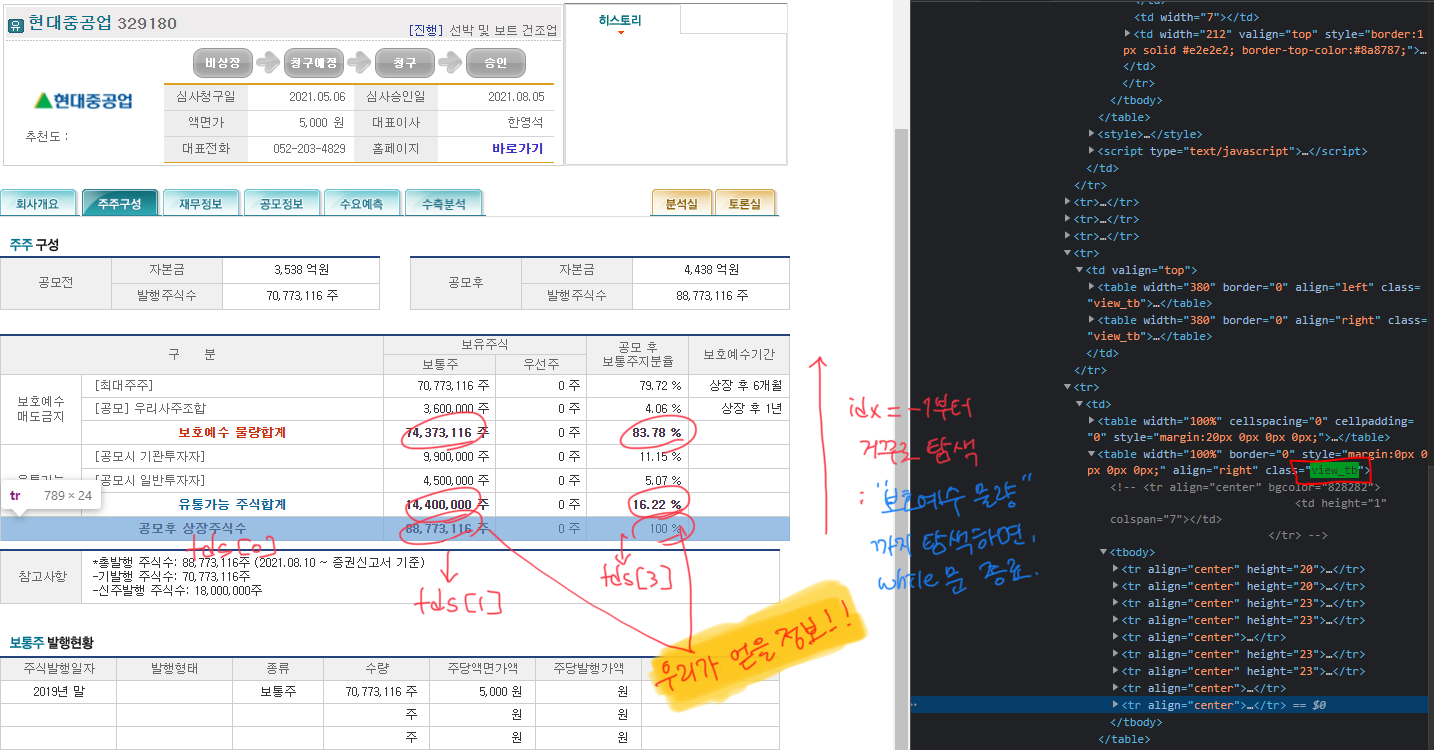
def get_shareholder_info_df(url, company_name):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
table = soup.select('table[class="view_tb"]')[2] #유통 가능 정보 테이블
table_rows = table.find_all('tr')
shares_info = []
idx = -1
while len(shares_info) < 3:
tds = table_rows[idx].find_all('td')
idx = idx - 1
target_text = tds[0].text.strip().replace('\t', '').replace('\r\n', '')
if target_text in ['공모후 상장주식수', '유통가능주식합계', '보호예수물량합계']:
number_of_shares = int(tds[1].text.strip().replace('주', '').replace(',', ''))
ratio_of_shares = tds[3].text.strip().replace(' ', '')
shares_info.append([number_of_shares, ratio_of_shares])
shareholder_info_df = pd.DataFrame({'종목명' : company_name,
'공모후 상장주식수(주식수)' : shares_info[0][0],
'공모후 상장주식수(비율)' : shares_info[0][1],
'유통가능주식합계(주식수)': shares_info[1][0],
'유통가능주식합계(비율)': shares_info[1][1],
'보호예수물량합계(주식수)': shares_info[2][0],
'보호예수물량합계(비율)': shares_info[2][1]}, index=[0])
return shareholder_info_df<3. 수요예측 탭 크롤링하기 : UrlTypeIndex.DEMAND_FORECAST>
아래 더보기 : 사진 및 코드 - 사진에 코드 이해를 위한 필기 기입
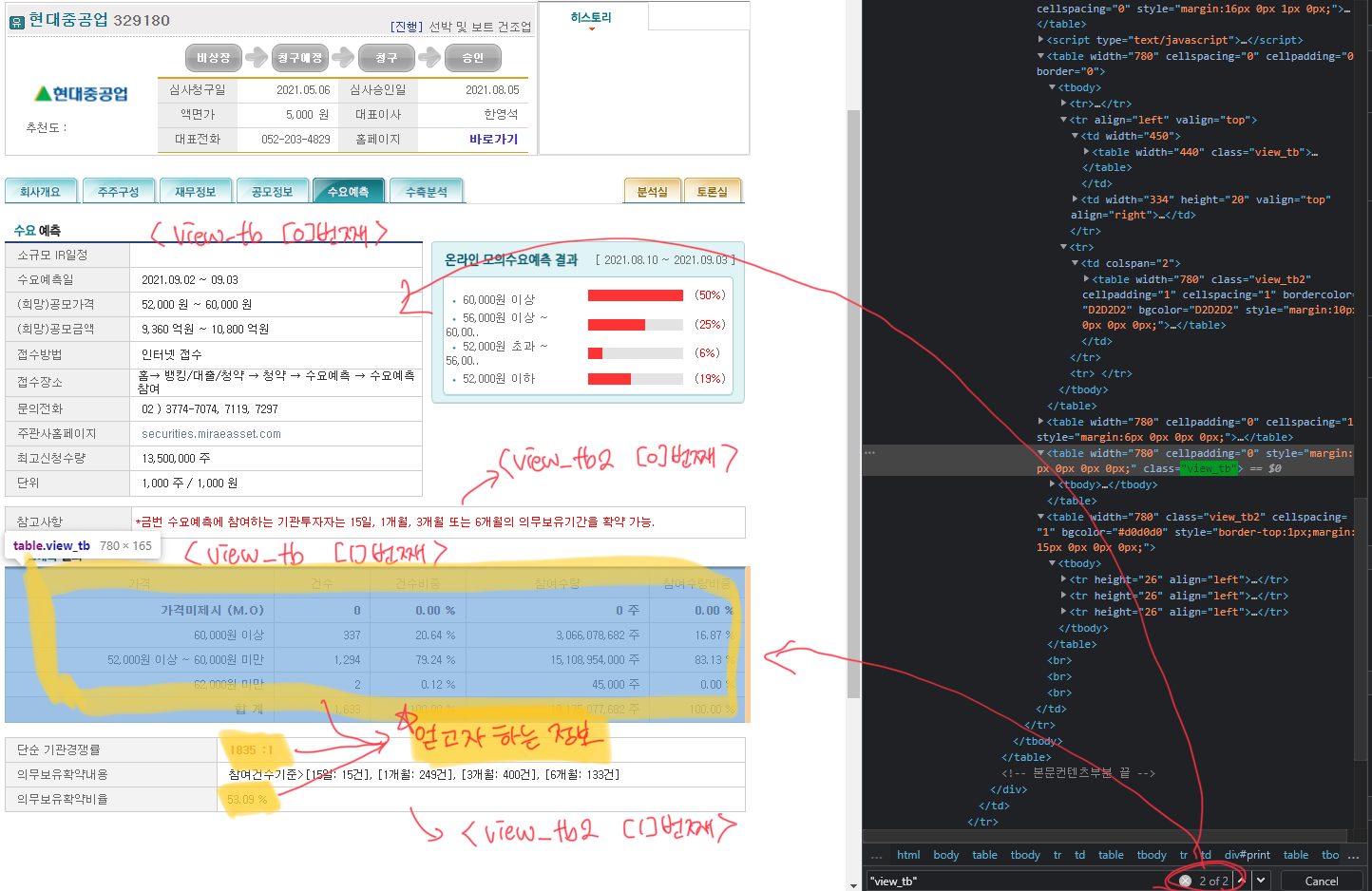
def get_demand_forecast_result_df(url, company_name):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
additional_info_table = soup.select('table[class="view_tb2"]')[1]
additional_info_rows = additional_info_table.find_all('tr')
del additional_info_rows[1]
competition_ratio = additional_info_rows[0].find_all('td')[1].text.strip().replace(' ', '').replace('\xa0', '')
commitment_ratio = additional_info_rows[1].find_all('td')[1].text.strip().replace(' ', '')
demand_forecast_df = pd.DataFrame({'종목명': company_name,
'기관경쟁률': competition_ratio,
'의무보유확약비율': commitment_ratio}, index=[0])
return demand_forecast_df
def get_demand_forecast_band_info_df(url, company_name):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
demand_forecast_result_table = soup.select('table[class="view_tb"]')[1]
demand_forecast_info_rows = demand_forecast_result_table.find_all('tr')[2:]
price_list = []
registration_num_list = []
registration_ratio_list = []
amount_list = []
amount_ratio_list = []
for result_row in demand_forecast_info_rows:
tds = result_row.find_all('td')
price_list.append(tds[0].text.strip())
registration_num_list.append(tds[1].text.strip())
registration_ratio_list.append(tds[2].text.strip())
amount_list.append(tds[3].text.strip())
amount_ratio_list.append(tds[4].text.strip())
demand_forecast_band_info_df = pd.DataFrame({'종목명' : [company_name] * len(price_list),
'가격': price_list,
'건수': registration_num_list,
'건수비중': registration_ratio_list,
'참여수량': amount_list,
'참여수량비중': amount_ratio_list,})
return demand_forecast_band_info_df<전체 코드>
import requests
from bs4 import BeautifulSoup
from enum import IntEnum
import pandas as pd
class UrlTypeIndex(IntEnum):
PUBLIC_OFFERING = 0 #공모정보
SHARE_HOLDER = 1 #주주구성
DEMAND_FORECAST = 2 #수요예측
def crawl_ipo_info(url):
url_list = []
url_list.append(url) # 공모정보 탭
for page_num in [2, 5]: # 주주구성, 수요예측 탭
search_required_url = url.replace('_04', f'_0{page_num}')
url_list.append(search_required_url)
bidding_info_df = get_bidding_info_df(url_list[UrlTypeIndex.PUBLIC_OFFERING])
company_name = bidding_info_df['종목명']
underwriter_df = get_underwriter_df(url_list[UrlTypeIndex.PUBLIC_OFFERING], company_name)
shares_info_df = get_shareholder_info_df(url_list[UrlTypeIndex.SHARE_HOLDER], company_name)
ipo_info_df = pd.merge(bidding_info_df, shares_info_df)
try:
demand_forecast_result_df = get_demand_forecast_result_df(url_list[UrlTypeIndex.DEMAND_FORECAST], company_name)
demand_forecast_band_info_df = get_demand_forecast_band_info_df(url_list[UrlTypeIndex.DEMAND_FORECAST], company_name)
ipo_info_df = pd.merge(ipo_info_df, demand_forecast_result_df)
except IndexError:
#청약 전날에 수요예측 결과가 늦게 표기되는 경우가 종종 있음
print("수요예측 결과 미표기")
return ipo_info_df
def get_bidding_info_df(url):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
tables = soup.select('table[class="view_tb"]')[0:3]
company_name = soup.find('strong', {'class': 'view_tit'}).text.strip()
date_table = tables[0]
price_table = tables[1]
allocation_ratio_table = tables[2]
date_df = get_date_info_df(date_table, company_name)
offering_price_df = get_offering_price_info_df(price_table, company_name)
allocation_ratio_df = get_allocation_ratio_df(allocation_ratio_table, company_name)
bidding_info_df = pd.merge(date_df, offering_price_df)
bidding_info_df = pd.merge(bidding_info_df, allocation_ratio_df)
return bidding_info_df
def get_date_info_df(date_table, company_name):
date_table_rows = date_table.find_all('tr')[2:]
del date_table_rows[-2]
temp_ipo_date_info = date_table_rows[0].find_all('td')[1].text.strip().replace('\xa0', '').replace(" ", "")
offering_start = temp_ipo_date_info[:10]
offering_finish = temp_ipo_date_info[:5] + temp_ipo_date_info[-5:]
refund_date = date_table_rows[1].find_all('td')[1].text.strip().replace('\xa0', '').replace(" ", "")
ipo_date = date_table_rows[2].find_all('td')[1].text.strip().replace('\xa0', '').replace(" ", "")
date_info_df = pd.DataFrame({'종목명': company_name,
'공모시작' : offering_start,
'공모마감' : offering_finish,
'환불일' : refund_date,
'상장일' : ipo_date}, index=[0])
return date_info_df
def get_offering_price_info_df(price_table, company_name):
price_table_rows = price_table.find_all('tr')[:-2]
del price_table_rows[1]
offering_price_band = price_table_rows[0].find_all('td')[1].text.strip().replace('\xa0', '').replace(' ', '').replace('원', '')
offering_price_band_low, offering_price_band_high = offering_price_band.split('~')
offering_price = price_table_rows[1].find_all('td')[1].text.strip().replace('\xa0', '').replace(' ', '').replace('원', '')
offering_amount = price_table_rows[2].find_all('td')[1].text.strip().replace('\xa0', '').replace(' ', '').replace('원', '')
offering_price_info_df = pd.DataFrame({'종목명': company_name,
'공모가하단' : offering_price_band_low,
'공모가상단': offering_price_band_high,
'공모가격' : offering_price,
'공모규모' : offering_amount}, index=[0])
return offering_price_info_df
def get_allocation_ratio_df(allocation_ratio_table, company_name):
allocation_ratio_table_rows = allocation_ratio_table.find_all('tr')
total_share_num = allocation_ratio_table_rows[0].find_all('td')[1].text.strip().replace('\xa0', '').replace(" ", "") # 0: 공모주식수
investor_num = allocation_ratio_table_rows[1].find_all('td')[2].text.strip().replace(" ", "") #1: 전문투자자
investor_ratio = allocation_ratio_table_rows[1].find_all('td')[3].text.strip().replace(" ", "")
employee_num = allocation_ratio_table_rows[2].find_all('td')[1].text.strip().replace(" ", "") #2: 우리사주조합
employee_ratio = allocation_ratio_table_rows[2].find_all('td')[2].text.strip().replace(" ", "")
public_num = allocation_ratio_table_rows[3].find_all('td')[1].text.strip().replace(" ", "") # 3: 일반청약자
public_ratio = allocation_ratio_table_rows[3].find_all('td')[2].text.strip().replace(" ", "")
foreigner_num = allocation_ratio_table_rows[4].find_all('td')[1].text.strip().replace(" ", "") # 4: 해외투자자
foreigner_ratio = allocation_ratio_table_rows[4].find_all('td')[2].text.strip().replace(" ", "")
allocation_ratio_df = pd.DataFrame({'종목명': company_name,
'공모주식수' : total_share_num,
'전문투자자(주식수)' : investor_num,
'전문투자자(비율)' : investor_ratio,
'우리사주조합(주식수)' : employee_num,
'우리사주조합(비율)' : employee_ratio,
'일반청약자(주식수)' : public_num,
'일반청약자(비율)' : public_ratio,
'해외투자자(주식수)': foreigner_num,
'해외투자자(비율)': foreigner_ratio}, index=[0])
return allocation_ratio_df
def get_shareholder_info_df(url, company_name):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
table = soup.select('table[class="view_tb"]')[2] #유통 가능 정보 테이블
table_rows = table.find_all('tr')
shares_info = []
idx = -1
while len(shares_info) < 3:
tds = table_rows[idx].find_all('td')
idx = idx - 1
target_text = tds[0].text.strip().replace('\t', '').replace('\r\n', '')
if target_text in ['공모후 상장주식수', '유통가능주식합계', '보호예수물량합계']:
number_of_shares = int(tds[1].text.strip().replace('주', '').replace(',', ''))
ratio_of_shares = tds[3].text.strip().replace(' ', '')
shares_info.append([number_of_shares, ratio_of_shares])
shareholder_info_df = pd.DataFrame({'종목명' : company_name,
'공모후 상장주식수(주식수)' : shares_info[0][0],
'공모후 상장주식수(비율)' : shares_info[0][1],
'유통가능주식합계(주식수)': shares_info[1][0],
'유통가능주식합계(비율)': shares_info[1][1],
'보호예수물량합계(주식수)': shares_info[2][0],
'보호예수물량합계(비율)': shares_info[2][1]}, index=[0])
return shareholder_info_df
def get_demand_forecast_result_df(url, company_name):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
additional_info_table = soup.select('table[class="view_tb2"]')[1]
additional_info_rows = additional_info_table.find_all('tr')
del additional_info_rows[1]
competition_ratio = additional_info_rows[0].find_all('td')[1].text.strip().replace(' ', '').replace('\xa0', '')
commitment_ratio = additional_info_rows[1].find_all('td')[1].text.strip().replace(' ', '')
demand_forecast_df = pd.DataFrame({'종목명': company_name,
'기관경쟁률': competition_ratio,
'의무보유확약비율': commitment_ratio}, index=[0])
return demand_forecast_df
def get_underwriter_df(url, company_name):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
underwriter_table = soup.select('table[class="view_tb"]')[3]
underwriter_rows = underwriter_table.find_all('tr')[1:]
#주간사 별 배정수량
underwriter_name_list = []
underwriter_quantity_list = []
for underwriter_row in underwriter_rows:
underwriter_name_list.append(underwriter_row.find_all('td')[0].text.strip().replace(" ", ""))
underwriter_quantity_list.append(underwriter_row.find_all('td')[1].text.strip().replace(" ", ""))
return pd.DataFrame({'종목명': [company_name]*len(underwriter_rows), '주간사' : underwriter_name_list, '배정수량' : underwriter_quantity_list})
def get_demand_forecast_band_info_df(url, company_name):
response = requests.get(url)
html = response.content.decode('utf-8', 'replace')
soup = BeautifulSoup(html, 'lxml')
demand_forecast_result_table = soup.select('table[class="view_tb"]')[1]
demand_forecast_info_rows = demand_forecast_result_table.find_all('tr')[2:]
price_list = []
registration_num_list = []
registration_ratio_list = []
amount_list = []
amount_ratio_list = []
for result_row in demand_forecast_info_rows:
tds = result_row.find_all('td')
price_list.append(tds[0].text.strip())
registration_num_list.append(tds[1].text.strip())
registration_ratio_list.append(tds[2].text.strip())
amount_list.append(tds[3].text.strip())
amount_ratio_list.append(tds[4].text.strip())
demand_forecast_band_info_df = pd.DataFrame({'종목명' : [company_name] * len(price_list),
'가격': price_list,
'건수': registration_num_list,
'건수비중': registration_ratio_list,
'참여수량': amount_list,
'참여수량비중': amount_ratio_list,})
return demand_forecast_band_info_df※회고
- 월말이 되면 추가로 다음 달 탭으로 넘어가서 청약 예정 종목을 추가로 탐색해야 된다.
- IPO 캘린더 : http://www.ipostock.co.kr/sub03/ipo06.asp?thisyear=2021&thismonth=9 를 이용하더라도, 매월 말일에는 다음 달로 넘어가야함 → 청약/상장 하루 전에 정보를 주는건 좋지만.. 계속 고민중이다..
- IPOSTOCK 홈페이지가 더 정보가 많은 줄 알았는데, 생각해보니까 38커뮤니케이션에서 동일한 방식으로 url을 타고 들어가면, html 코드에 있어 Class 및 ID 부여도 더 잘되어 있어 38커뮤니케이션에서도 크롤링하는 코드를 추가적으로 짜서 한 쪽 홈페이지에 문제가 생겼을 때, 차선책이 있기 때문에 정상적으로 작동할 수 있을 것 같다.