블로그를 시작하기 전에 코드를 미리 꽤 작성해뒀는데, 38커뮤니케이션에서 2-1에 했던 것처럼 href 값을 가져와서 종목별 url에 들어가서 크롤링 할 생각을 하지 않고 참고할 코드가 있었기에 아래 참고글을 통해 크롤링을 했었다.
[02. 웹크롤링] 004. 38커뮤니케이션 – IPO 데이터
38커뮤니케이션은 장외주식, IPO 등 다양한 정보를 제공한다. 이 사이트를 통해서 IPO 예정인 기업들을 크롤링해보도록 하자. 비상장주식,장외주식시장 NO.1 38커뮤니케이션 종목명 청구일 자본금(
yonelabs.tistory.com
그래서 다시 코드를 작성했다.
(오픈 소스를 활용하는 건 좋지만, 진짜 100% 내 코드로 이번 프로젝트를 하고 싶다! - 물론 참고 정도는 계속 하고 있다.)
38커뮤니케이션에서도 동일한 방식으로 url을 타고 들어가면, html 코드에 있어 Class 및 ID 부여도 더 잘되어 있는 줄 알았지만, 몇개는 안되있었다! 그래도 이왕 하기로 마음 먹었기 때문에, 새로 크롤링 하는 중이다.
38커뮤니케이션에서도 크롤링하는 코드를 추가적으로 짜서 한 쪽 홈페이지에 문제가 생겼을 때, 차선책이 있기 때문에 정상적으로 작동할 수 있을 것 같기 때문이다!
저번과 같은 방식으로, 아래 38커뮤니케이션 사이트에서 공모주 관련 정보를 크롤링하려고 한다.
38커뮤니케이션 - 비상장주식,장외주식시장 NO.1
비상장주식,장외주식시장 NO.1 38커뮤니케이션.비상장거래/매매,시세정보,IPO기업분석,공모주,상장폐지주식,퇴출종목,K-OTC,코넥스 정보 제공
www.38.co.kr
IPO/공모 -> 공모주청약 일정, 신규상장을 누르면 크롤링 하고자 하는 종목들이 나온다.
- 공모주 청약 일정 탭 : http://www.38.co.kr/html/fund/index.htm?o=k&page={n}
- 신규 상장 탭 : http://www.38.co.kr/html/fund/index.htm?o=nw&page={n}
위 url과 같이, 탭 페이지수를 넘길때마다 url이 변경되기 때문에 나중에 DB에 한번에 넣을 때 참고하면 되겠다.
전과 동일하게 종목명을 누르면 더 상세한 정보들을 볼 수 있는 페이지로 넘어가는데, 종목마다 다른 코드를 가지고 있기 때문에 하이퍼링크(a태그의 href값)를 통해 종목별 페이지를 얻을 수 있었다.
ipostock과 다른점은,
1. 청약/상장이 끝난 종목들은 검정색(#333333, 333333) → font color 값이 신규상장 탭에는 #이 떼어져 있다.
2. 청약중/상장 당일 종목들은 빨간색(#E3231E, E3231E) → 위와 마찬가지로, 신규상장에는 #이 떼어있다.
3. 청약/상장 예정 종목들은 파랑색(#0066CC, 0066CC) → 위와 마찬가지로, 신규상장에는 #이 떼어있다.
4. 크롤링 할 테이블의 summary가 "공모주 청약일정", "신규상장종목" 으로 정해져 있어 soup.find('table', {'summary': table_summary})와 같은 메소드를 사용할 수 있다.
아래 더보기는 위 설명에 대한 사진이다.


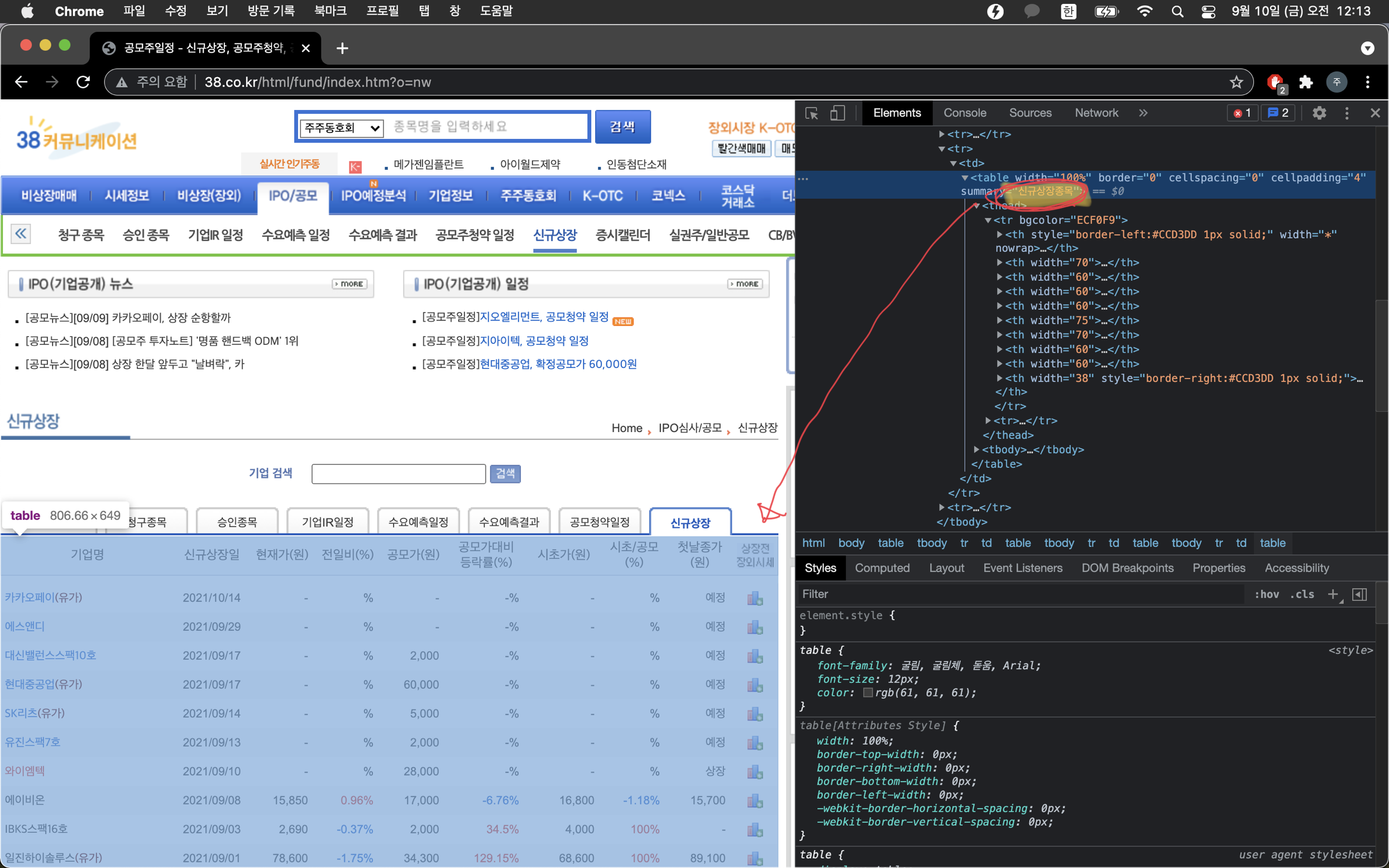
<공모청약 일정, 신규상장 크롤링에서 공통이 되는 table 요소를 얻어오기 위한 코드>
def get_table_rows(table_summary):
url_to_crawl = ''
url_dictionary = {
'공모주 청약일정': 'http://www.38.co.kr/html/fund/index.htm?o=k&page=1',
'신규상장종목': 'http://www.38.co.kr/html/fund/index.htm?o=nw&page=1',
}
try:
url_to_crawl = url_dictionary[table_summary]
except Exception as e:
print(e)
print("Wrong Table Summary")
response = requests.get(url_to_crawl, headers={'User-Agent': 'Mozilla/5.0'})
html = response.text
soup = BeautifulSoup(html, 'lxml')
data = soup.find('table', {'summary': table_summary})
table_rows = data.find_all('tr')[2:]
return table_rowstr 태그 0, 1번째는 head부분이 딸려 놔와서 slicing 하였다.
table_summary로 "공모주 청약일정", "신규상장종목"을 받으며 사실 다른게 들어올 일은 없지만 예외처리도 살짝 해주었다.
다른 값이 들어오면, KeyError가 날 수 있도록 dictionary로 구성해봤다.(조건문 보다 멋있어 보여서?ㅎㅎ)
<종목 상태 (1)청약/상장 이미 끝남 (2)청약 중, 상장일, (3)청약/상장 예정을 체크하는 CheckStatus 클래스>
base_url = 'http://www.38.co.kr'
class CheckStatus:
def __init__(self, type):
if type == 'BIDDING':
self.RGB_BLACK = '#333333'
self.RGB_RED = '#E3231E'
self.RGB_BLUE = '#0066CC'
elif type == 'IPO':
self.RGB_BLACK = '333333'
self.RGB_RED = 'E3231E'
self.RGB_BLUE = '0066CC'
def is_finished(self, tr):
return True if tr.find('font', attrs={'color': self.RGB_BLACK}) else False
def is_started(self, tr):
return True if tr.find('font', attrs={'color': self.RGB_RED}) else False
def is_scheduled(self, tr):
return True if tr.find('font', attrs={'color': self.RGB_BLUE}) else False클린코드라는 책을 보고, 잘 읽히는 코드를 구성하기 위해 억지로라도 클래스를 구성해서 가독성이 좋도록 노력해봤다.
- base_url은 아래 코드에서 사용된다.
위에서 말했듯이 공모청약일정 탭과 신규상장 탭에서 html font color가 #의 유무 차이가 있기 때문에,
- 공모청약일정 탭을 크롤링 할 땐, 객체 생성시 'BIDDING'을 argument로 전달하고,
- 신규상장 탭을 크롤링 할 땐, 객체 생성시 'IPO'를 전달하여 종목의 크롤링 여부 및 담길 list를 판단하는 boolean 값을 return 한다.
- 종목의 상태 파악은, 크롤링한 각 종목의 td 값 안 font를 색이 같으면 True, 아니면 False를 return 하도록 하였다.
<공모청약 일정 url 가져오기 : 청약 하루전, 청약 시작, 청약 마감일>
def get_bidding_url_list(target_date):
table_rows = get_table_rows('공모주 청약일정')
bidding_day_start_url_list = []
bidding_day_finish_url_list = []
bidding_day_before_url_list = []
checkBiddingStatus = CheckStatus('BIDDING')
for i in range(-1, -len(table_rows), -1):
table_row = table_rows[i].td
if checkBiddingStatus.is_finished(table_row):
continue
elif checkBiddingStatus.is_started(table_row):
date_info = table_rows[i].text.replace('\xa0', '').replace(" ", "").split('\n')[2]
bidding_start_date = datetime.strptime(date_info[:10], '%Y.%m.%d')
bidding_finish_date = datetime.strptime(date_info[:5] + date_info[-5:], '%Y.%m.%d')
#리츠의 경우, 3거래일 동안 청약 진행 -> 2틀차는 그냥 청약 시작으로 한번 더 공지
day_diff_bidding_start = target_date.day - bidding_start_date.day
day_diff_bidding_finish = target_date.day - bidding_finish_date.day
if day_diff_bidding_start == 0:
url = base_url + table_rows[i].select("a[href^='/html/fund/?o=v']")[0]['href']
bidding_day_start_url_list.append(url)
elif day_diff_bidding_finish == 0:
url = base_url + table_rows[i].select("a[href^='/html/fund/?o=v']")[0]['href']
bidding_day_finish_url_list.append(url)
elif checkBiddingStatus.is_scheduled(table_row):
date_info = table_rows[i].text.replace('\xa0', '').replace(" ", "").split('\n')[2]
bidding_start_date = datetime.strptime(date_info[:10], '%Y.%m.%d')
day_diff_bidding_start = bidding_start_date.day - target_date.day
if day_diff_bidding_start == 1:
url = base_url + table_rows[i].select("a[href^='/html/fund/?o=v']")[0]['href']
bidding_day_before_url_list.append(url)
else:
break
return [bidding_day_before_url_list, bidding_day_start_url_list, bidding_day_finish_url_list]- 바로 위에서 말한 것과 같이, 종목의 청약 상태를 확인하는 checkBiddingStatus 객체를 생성할 때 'BIDDING'을 argument로 전달하였다.
- 종목 글자 색이 빨간색(is_started == True)이면, 청약 시작일인지 마감일인지 day_diff_bidding_start, finish 변수로 확인한다.
- 리츠 종목의 경우 3거래일 동안 청약이 진행되지만 인기가 없고 비례 100% 종목이기 때문에, 2틀차도 그냥 청약 시작으로 공지하기로 하였다.(별로 인기도 없는데, 조건문 하나를 더 써서 더럽히고 싶지 않았다!)
- 종목 글자 색이 파란색(is_scheduled() == True)이면, 청약 시작 하루 전 종목만 골라낸다.
- 청약 2틀 이상 남은 종목들을 탐색하면, for문을 종료한다.
<신규상장 일정 url 가져오기 : 상장 하루전, 상장일>
def get_ipo_url_list(target_date):
table_rows = get_table_rows('신규상장종목')
ipo_day_before_url_list = []
ipo_d_day_url_list = []
checkIPOStatus = CheckStatus('IPO')
for i in range(-1, -len(table_rows), -1):
table_row = table_rows[i].td
if checkIPOStatus.is_finished(table_row):
continue
elif checkIPOStatus.is_started(table_row):
date_info = table_rows[i].text.replace('\xa0', '').replace(" ", "").split('\n')[2]
ipo_start_date = datetime.strptime(date_info, '%Y/%m/%d')
href = table_rows[i].select("a[href^='./?o=v&no']")[0]['href']
url = base_url + '/html/fund' + href[1:]
ipo_d_day_url_list.append(url)
elif checkIPOStatus.is_scheduled(table_row):
date_info = table_rows[i].text.replace('\xa0', '').replace(" ", "").split('\n')[2]
ipo_start_date = datetime.strptime(date_info, '%Y/%m/%d')
day_diff_ipo_start = ipo_start_date.day - target_date.day
if day_diff_ipo_start == 1:
href = table_rows[i].select("a[href^='./?o=v&no']")[0]['href']
url = base_url + '/html/fund' + href[1:]
ipo_day_before_url_list.append(url)
else:
break
return [ipo_day_before_url_list, ipo_d_day_url_list]공모청약 일정 url을 가져오는 로직과 동일하게 코드를 구성하였다.
아래는 더보기는 <전체 코드>이다.
import requests
from bs4 import BeautifulSoup
from datetime import datetime
base_url = 'http://www.38.co.kr'
class CheckStatus:
def __init__(self, type):
if type == 'BIDDING':
self.RGB_BLACK = '#333333'
self.RGB_RED = '#E3231E'
self.RGB_BLUE = '#0066CC'
elif type == 'IPO':
self.RGB_BLACK = '333333'
self.RGB_RED = 'E3231E'
self.RGB_BLUE = '0066CC'
def is_finished(self, tr):
return True if tr.find('font', attrs={'color': self.RGB_BLACK}) else False
def is_started(self, tr):
return True if tr.find('font', attrs={'color': self.RGB_RED}) else False
def is_scheduled(self, tr):
return True if tr.find('font', attrs={'color': self.RGB_BLUE}) else False
def get_table_rows(table_summary):
url_to_crawl = ''
url_dictionary = {
'공모주 청약일정': 'http://www.38.co.kr/html/fund/index.htm?o=k&page=1',
'신규상장종목': 'http://www.38.co.kr/html/fund/index.htm?o=nw&page=1',
}
try:
url_to_crawl = url_dictionary[table_summary]
except Exception as e:
print(e)
print("Wrong Table Summary")
response = requests.get(url_to_crawl, headers={'User-Agent': 'Mozilla/5.0'})
html = response.text
soup = BeautifulSoup(html, 'lxml')
data = soup.find('table', {'summary': table_summary})
table_rows = data.find_all('tr')[2:]
return table_rows
def get_bidding_url_list(target_date):
table_rows = get_table_rows('공모주 청약일정')
bidding_day_start_url_list = []
bidding_day_finish_url_list = []
bidding_day_before_url_list = []
checkBiddingStatus = CheckStatus('BIDDING')
for i in range(-1, -len(table_rows), -1):
table_row = table_rows[i].td
if checkBiddingStatus.is_finished(table_row):
continue
elif checkBiddingStatus.is_started(table_row):
date_info = table_rows[i].text.replace('\xa0', '').replace(" ", "").split('\n')[2]
bidding_start_date = datetime.strptime(date_info[:10], '%Y.%m.%d')
bidding_finish_date = datetime.strptime(date_info[:5] + date_info[-5:], '%Y.%m.%d')
#리츠의 경우, 3거래일 동안 청약 진행 -> 2틀차는 그냥 청약 시작으로 한번 더 공지
day_diff_bidding_start = target_date.day - bidding_start_date.day
day_diff_bidding_finish = target_date.day - bidding_finish_date.day
if day_diff_bidding_start == 0:
url = base_url + table_rows[i].select("a[href^='/html/fund/?o=v']")[0]['href']
bidding_day_start_url_list.append(url)
elif day_diff_bidding_finish == 0:
url = base_url + table_rows[i].select("a[href^='/html/fund/?o=v']")[0]['href']
bidding_day_finish_url_list.append(url)
elif checkBiddingStatus.is_scheduled(table_row):
date_info = table_rows[i].text.replace('\xa0', '').replace(" ", "").split('\n')[2]
bidding_start_date = datetime.strptime(date_info[:10], '%Y.%m.%d')
day_diff_bidding_start = bidding_start_date.day - target_date.day
if day_diff_bidding_start == 1:
url = base_url + table_rows[i].select("a[href^='/html/fund/?o=v']")[0]['href']
bidding_day_before_url_list.append(url)
else:
break
return [bidding_day_before_url_list, bidding_day_start_url_list, bidding_day_finish_url_list]
def get_ipo_url_list(target_date):
table_rows = get_table_rows('신규상장종목')
ipo_day_before_url_list = []
ipo_d_day_url_list = []
checkIPOStatus = CheckStatus('IPO')
for i in range(-1, -len(table_rows), -1):
table_row = table_rows[i].td
if checkIPOStatus.is_finished(table_row):
continue
elif checkIPOStatus.is_started(table_row):
date_info = table_rows[i].text.replace('\xa0', '').replace(" ", "").split('\n')[2]
ipo_start_date = datetime.strptime(date_info, '%Y/%m/%d')
href = table_rows[i].select("a[href^='./?o=v&no']")[0]['href']
url = base_url + '/html/fund' + href[1:]
ipo_d_day_url_list.append(url)
elif checkIPOStatus.is_scheduled(table_row):
date_info = table_rows[i].text.replace('\xa0', '').replace(" ", "").split('\n')[2]
ipo_start_date = datetime.strptime(date_info, '%Y/%m/%d')
day_diff_ipo_start = ipo_start_date.day - target_date.day
if day_diff_ipo_start == 1:
href = table_rows[i].select("a[href^='./?o=v&no']")[0]['href']
url = base_url + '/html/fund' + href[1:]
ipo_day_before_url_list.append(url)
else:
break
return [ipo_day_before_url_list, ipo_d_day_url_list]※회고
- 월말이 되면 추가로 다음 달 탭으로 넘어가서 청약 예정 종목을 추가로 탐색해야 되는 불편함은 없어졌지만,
- 9/10일 기준 공모청약일정 탭에 25종목이 list 되어 있다. 만약 청약 예정 종목수가 많아서
한 페이지를 꽉 채우고도 넘길 정도의 '대상장의 시대'가 왔을 때 어떻게 해야할지도 생각해봐야 한다.
- 신규 상장 예정 종목이 많을 때도 마찬가지이다.
- 9/10(금) 15시 : 자기 전 생각났던 문제점이 이제서야 생각났다. target_date를 기준으로 크롤링 해오지만, 홈페이지는 오늘 날짜 기준으로 글자 색을 표기하기 때문에 크롤링 해오려는 target_date가 오늘이 아닌 이상 원하는 데이터를 가져오지 못하므로 코드를 다시 수정해야될 것 같다.
- 당일 알림으로써 코드는 좋지만, 확장성 면에서 매우 좋지 않은 코드를 작성한 것 같다.
'Side Projects > 공모주 알리미' 카테고리의 다른 글
| [공모주 알리미 개발] 2-4. 38커뮤니케이션 크롤링 : 기업 개요, 공모 정보, 청약 일정 가져오기 (0) | 2021.11.23 |
|---|---|
| [공모주 알리미 개발] 2-3. 38커뮤니케이션 크롤링 : 종목별 url 추출하기(수정) (0) | 2021.11.22 |
| [공모주 알리미 개발] 2-2. ipostock 크롤링 : 주주구성, 공모정보, 수요예측 정보 가져오기 (0) | 2021.09.06 |
| [공모주 알리미 개발] 2-1. ipostock 크롤링 : 종목별 url 추출하기 (0) | 2021.08.30 |
| [공모주 알리미 개발] 1. 개요 (3) | 2021.08.26 |